
This morning, Opsgenie alerted me that the Production API for xTravel had stopped responding to requests. I took a quick 30 seconds and confirm that xTravel has indeed stopped responding but my main webpage at alexlamond.co.uk had not. My workflow sent Statuspage into red across the board. Uh oh.
I got a chance on my break from work to try a few things. I jumped into the Plesk admin panel and tried to reboot Apache, no change, any domain using PHP either timed out or returned a 504. Let’s restart PHP then. Still no change. Better make sure we’ve not hit CPU/Memory limits that are causing PHP to timeout. They’re small services but let’s stop Dovecot and SMTP/IMAP servers I think to myself. Still, we’re down.
The 504 is reporting from NGINX so let’s reboot it. Failed to reboot. Odd. Try again. Failed again. Weird. Let’s stop it all together then. Stopped. Start service. Failed. Uh oh… Let’s restart PHP again make sure its not hanging back. PHP stopped, can’t re-start. Everything I’m doing puts me in a worse place. My homepage shows the default Plesk domain page, at-least at the start it showed my BLM message, this is bad…
I bit the bullet and rebooted the server. I hate doing it because I have a few scripts I have to run and items to disable afterwords (Really I should tidy them up, as what happened next was thanks to the latter)
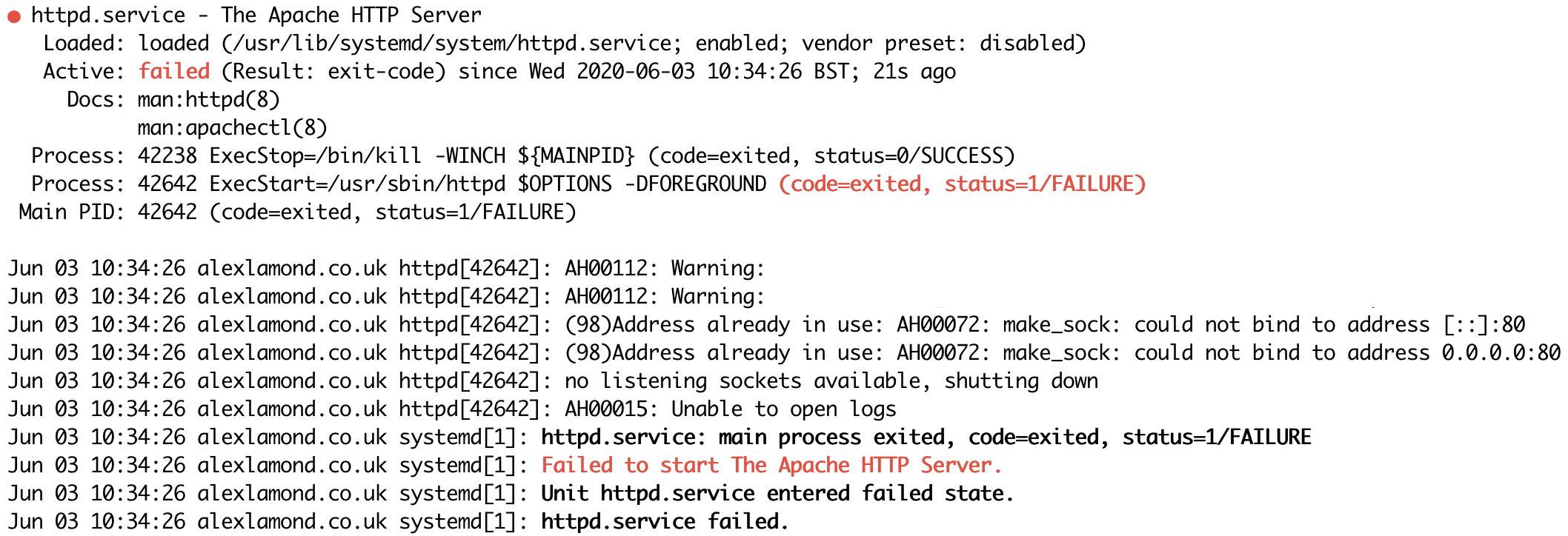
Okay, server rebooted. Apache failed to start and NGNIX is still not starting. GRRRRR. service httpd status

Now Apache can’t open a connection on port 80, as I pointed out in the second to last paragraph, due to a lovely startup script. A quick check of what was using what port (lsof -i -P -n | grep LISTEN) followed by killing the offending service and disabling it so it never happens again and service httpd start succeeds
Now, the pressing issue of why NGINX still would not start. I try instead to start it from CLI instead of the Plesk Admin Panel. service nginx start made no difference and service nginx status provided a pretty vague error message..

I knew a reboot was not going to fix this, Apache started fine, PHP was up and running after the reboot and NGINX was saying nothing about needing ports opened or having ports taken over. A quick internet search of ‘Failed to start Startup script for nginx service’ returned the answer. A post on the Plesk forums less than a week ago (https://support.plesk.com/hc/en-us/articles/360020513833-Cannot-start-nginx-service-on-Plesk-server-Failed-to-start-Startup-script-for-nginx-service) showed someone else also had NGINX randomly crash on them and be unrecoverable. The difference here, a solution
plesk sbin nginxmng -d was placed into the server command prompt and within seconds, my own monitoring tool and Opsgenie flooded me with alerts that the web server was back online and I needed to run my scripts (That I mentioned earlier) to achieve full operation. I decided to play it safe and also ran plesk sbin nginxmng -e – No harm came from running it, thankfully, and for the last two two or three hours, sever performance has been back to normal.
Now it’s a waiting game to see if the same issue occurs tomorrow. I have no idea what caused it to happen, or what changed, but boy, that was not fun.